Building speech-enabled applications consists of 2 steps in addition to traditional application development:
1. Capturing voice commands/queries and translating these to human-readable text.
2. Translating these text commands/queries to computer commands.
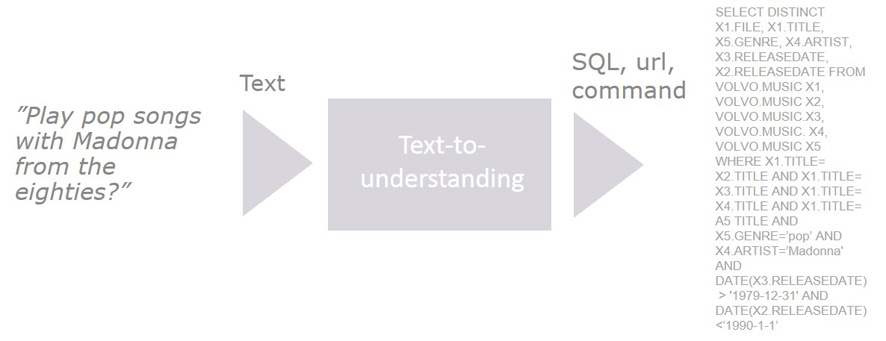
As an illustration DialogueTech’s music application Personal Dj allows you to select and play songs on a mobile phone with voice commands formulated in the user’s own words. Application data such as audio files with music is often stored in relational databases such as SQLite, which is supported for all three major smartphone operating systems, Android, Windows Phone and iOS. To retrieve data you use the database language SQL.
The first step above is accomplished using a speech recognition package. Speech recognition packages exist for operating systems like Android as well as in the form of independent speech recognition packages from companies like Nuance. The output from a speech recognition software is a piece of human-readable text, sometimes accompanied by some number representing the estimated accuracy of the analysis of the user’s utterance.
The conversion of an utterance from human-readable text to a computer command is the core competence of DialogueTech and the Ergo engine. Request for songs to be played are translated to SQL commands which are sent to the database where e.g. the music files are stored. Once retrieved these are passed on to a media player for playback.
Packaging these two components in an application gives you a uniquely flexible voice-enabled application with a minimal development effort and ready to be carried over to multiple other languages.
Check out or sample application Personal Dj here!
Check out a video demonstrating an in-car voice operated manual here!
What is unique with Ergo from DialogueTech
Ergo is based on world-leading technology for understanding of natural language (the language humans speak). Every question or command is analyzed both syntactically, to verify that it is e.g. proper English, and semantically to make sure that it has a meaning.
The syntactic analysis is carried out with the help of a grammar for the language used. It will make sure that commands like Pray mother pop song from the eighties with Madonna are sorted out and the user can be asked for clarification. Grammars don’t depend on the application and the same grammar can be used for all applications in a specific language, e.g. English. Speech recognition software not seldom outputs grammatically incorrect results which are meaningless.
The sematic analysis is made with the help of a domain model, which describes the world for the computer. The phrases We gave the monkeys bananas because they were over-ripe and We gave the monkeys bananas because they were hungry are both grammatically correct, but you need to teach the system that monkeys can be hungry but not over-ripe. The domain model is specific for a particular application and can be reused in other languages. Similar to before speech recognition software not seldom outputs grammatically correct results which are meaningless.
Unless you know that something is wrong you can’t fix it!
Combined this allows for developing uniquely accurate and user-friendly applications in a cost-effective way, reusing previous applications. This is supported by extensive documentation and development tools. In addition Ergo-based applications will run on anything from a low-end smartphone to a mainframe computer.
You can read more about DialogueTech here!