Application Flow
An application goes through the following processing stages (simplified model).

The speech recognition front-end translates the utterance to human-readable text. Additionally some speech recognition packages can output several interpretations together with an estimate for how accurate the interpretation is in the form of some number. These other interpretations can be used for e.g. error handling.
The pre-processing preforms a few minor adaptations of the user query to suit the Ergo engine.
The Ergo module contains the language-specific grammar, the application-specific domain model and the logic for resolving natural language phrases.
Post-processing takes care of the output from Ergo and performs any disambiguation and handles any errors.
The user interface and application logic usually resides in the host software program and contains code for making use of the output from Ergo and presenting the result to the user.
More information about the pre- and post-processing can be found here!
Application Components
As an illustration of the components in a typical application we use the Personal Dj on Android.
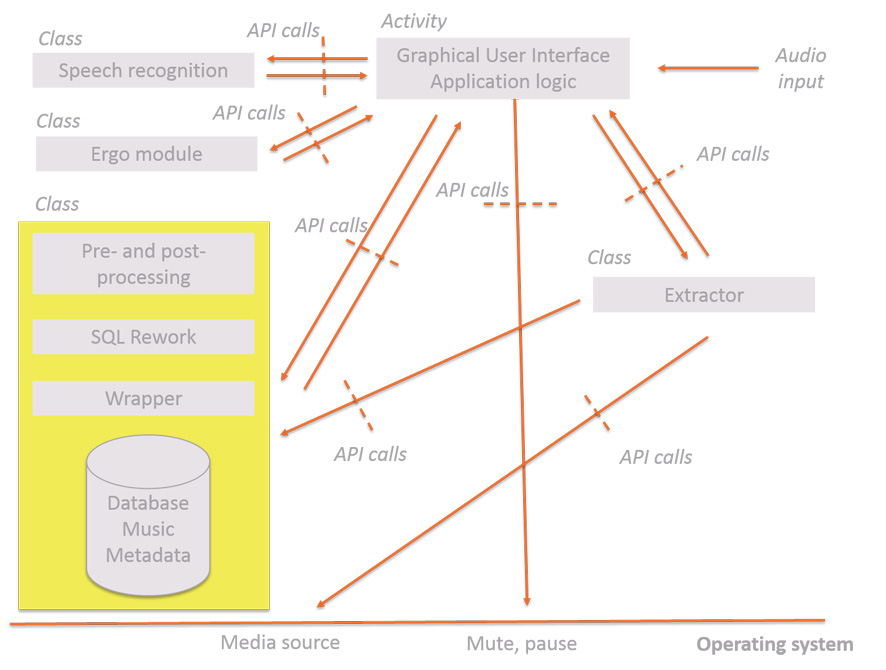
In this particular case the audio files are stored in a file system.
The Extractor searches the file system for audio files, reads the metadata in all audio files and stores this in a database, together with the url for each file. Source code for the extractor is found here! [DTAndroidExtractor.java]
SQL Rework and is involves any changes to the SQL queries which are output from the Ergo Engine to take care of any specifics of the particular database. As an illustration the source code for SQL Rewrite for SQLite on Android is found here! [Ergo.java]
Pre-processing involves rewriting the query before it is passed to the Engine module. Things which need to be modified include replacing single quotes (‘) with double quotes (‘’), underscore (_) with space ( ) as well as replacing some expressions like sixties with between 1959 and 1970, etc. An illustration of this is found here! [Ergo.java]
Post-processing takes care of the output from the database, including any error messages and passes these on to the Graphical User Interface and Application Logic. An example of Post-processing source code is found here! [TBD]
The Database with Music Metadata is used in the Personal Dj because audio files in this particular case are not stored in a database but in a file system. With the help of the Extractor the metadata is extracted from the audio files and stored in the database. Metadata is used for selecting songs to listen to.
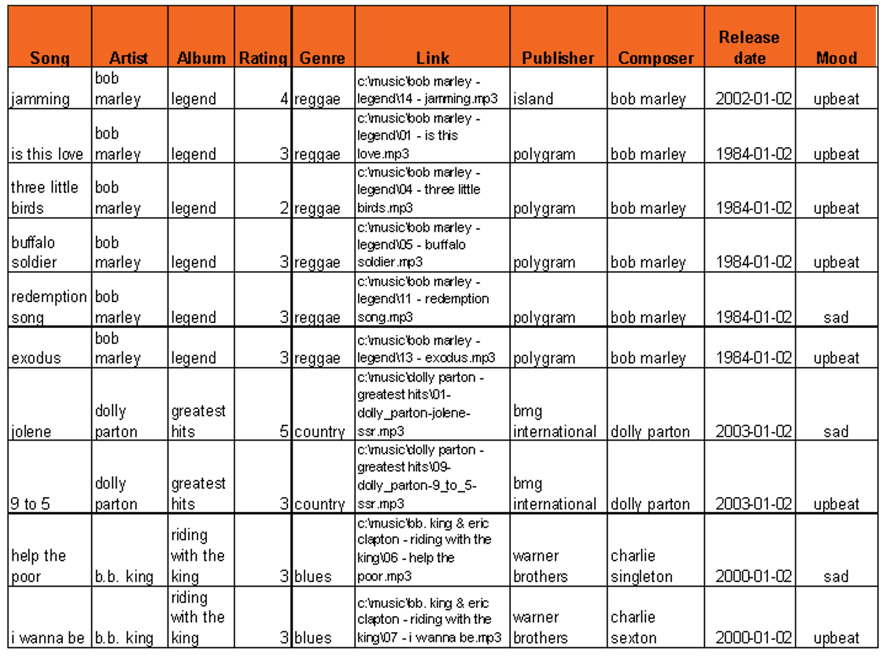
The query Play reggae songs with Bob Marley from the eighties results in the SQL query
SELECT DISTINCT X1.FILE, X1.TITLE, X5.GENRE, X4.ARTIST, X3.RELEASEDATE, X2.RELEASEDATE
FROM VOLVO.MUSIC X1, VOLVO.MUSIC X2, VOLVO.MUSIC.X3, VOLVO.MUSIC. X4, VOLVO.MUSIC X5
WHERE X1.TITLE= X2.TITLE AND X1.TITLE= X3.TITLE AND X1.TITLE= X4.TITLE AND X1.TITLE= A5 TITLE AND X5.GENRE=’reggae’ AND X4.ARTIST=’Bob Marley’ AND DATE(X3.RELEASEDATE) > ‘1979-12-31’ AND DATE(X2.RELEASEDATE) <’1990-1-1’
The corresponding links are subsequently sent to the media player for playback.
The function of the Graphical User Interface and Application Logic depends on the application. In the Personal Dj by DialogueTech users can control a media player with free-format voice commands. The source code is found here! [TBD]
The Speech Recognition is a commercial speech recognition package, e.g. like the SpeechRecognizer class in Android.
The Ergo Module
The Ergo Module performs the syntactic and semantic analysis and compiles the SQL command corresponding to the user’s question or command.
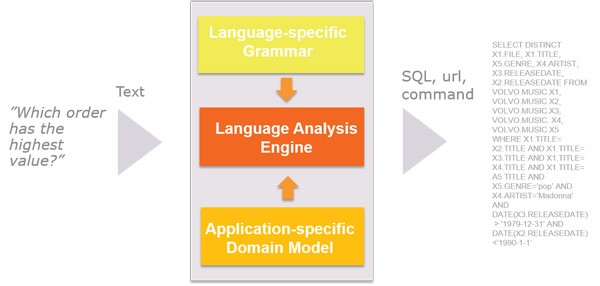
Language-specific Grammar contains the linguistic rules for the language used in the application (e.g. English). It can be thought of as an ordinary university grammar book written in a special format. It is generic to the language and does nor depend on the specific application.
Language Analysis Engine contains the core logic to analyze the users query and translate that to e.g. a SQL command.
Application-specific Domain Model contains the binary entity relationship model used to describe the domain the application should cover (sometimes referred to as Universe of Discours, or UoD). This model defines the concepts the application should be aware of and how they relate to each other. In the example We gave the monkeys bananas because they were over-ripe and We gave the monkeys bananas because they were hungry the adjective over-ripe is connected to the bananas and the adjective hungry is connected to the monkeys.